




Why Agentic RAG Deserves a Different Implementation Lens?
In one of our early builds, the agent was tasked with handling onboarding across HR, IT, and compliance – pulling data, making API calls, and guiding the user through a multi-step workflow.
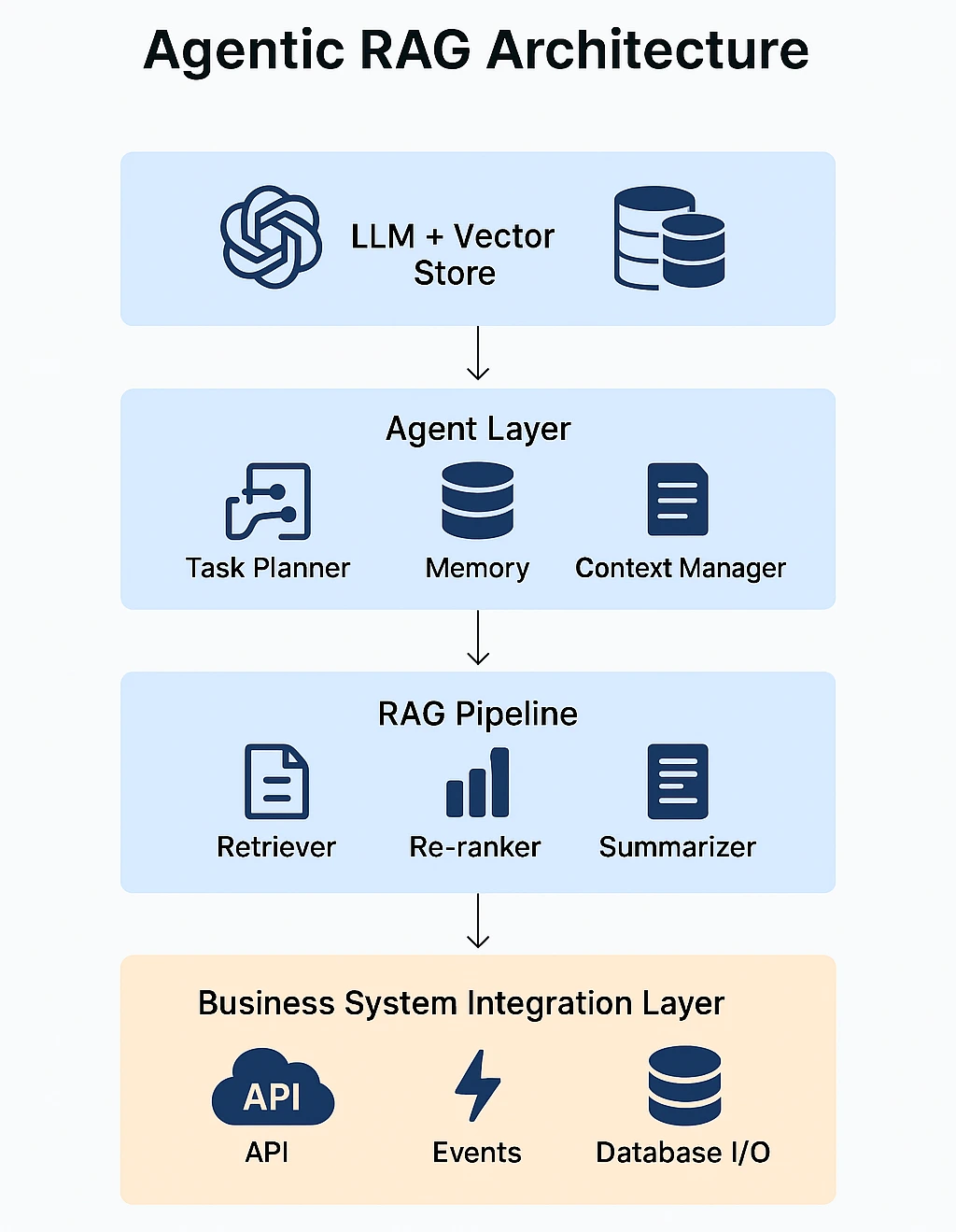
The initial setup looked solid: vector store, retriever, LLM – all connected. But as soon as the agent had to remember past steps, plan next actions, and respond in context, the system started falling apart. The architecture wasn’t built for reasoning or orchestration.
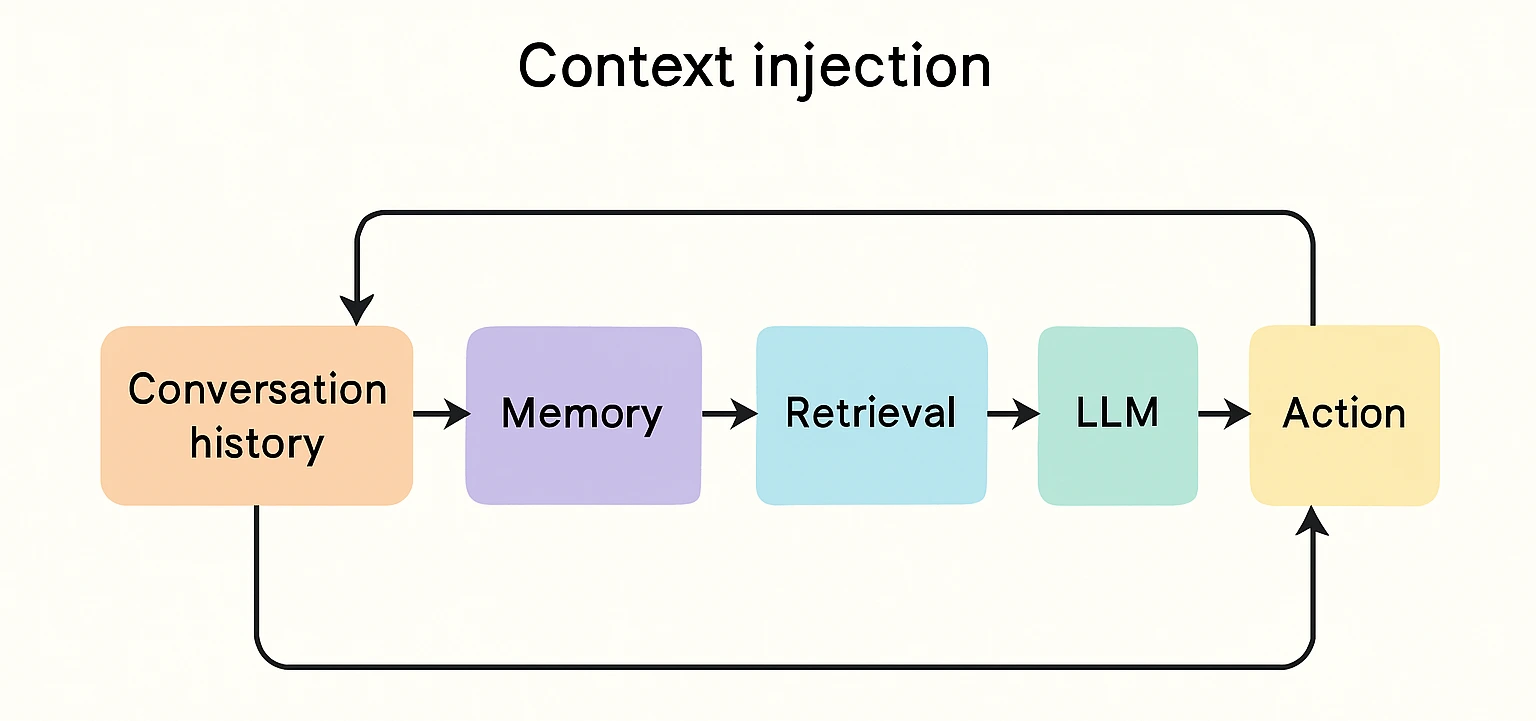
That’s when it clicked: Agentic RAG is also about coordinated decision-making, not just better retrieval. It demands memory, planning logic, dynamic context injection, and controlled system access, all working together.
From that point forward, we stopped thinking in terms of Q&A and started building for execution.
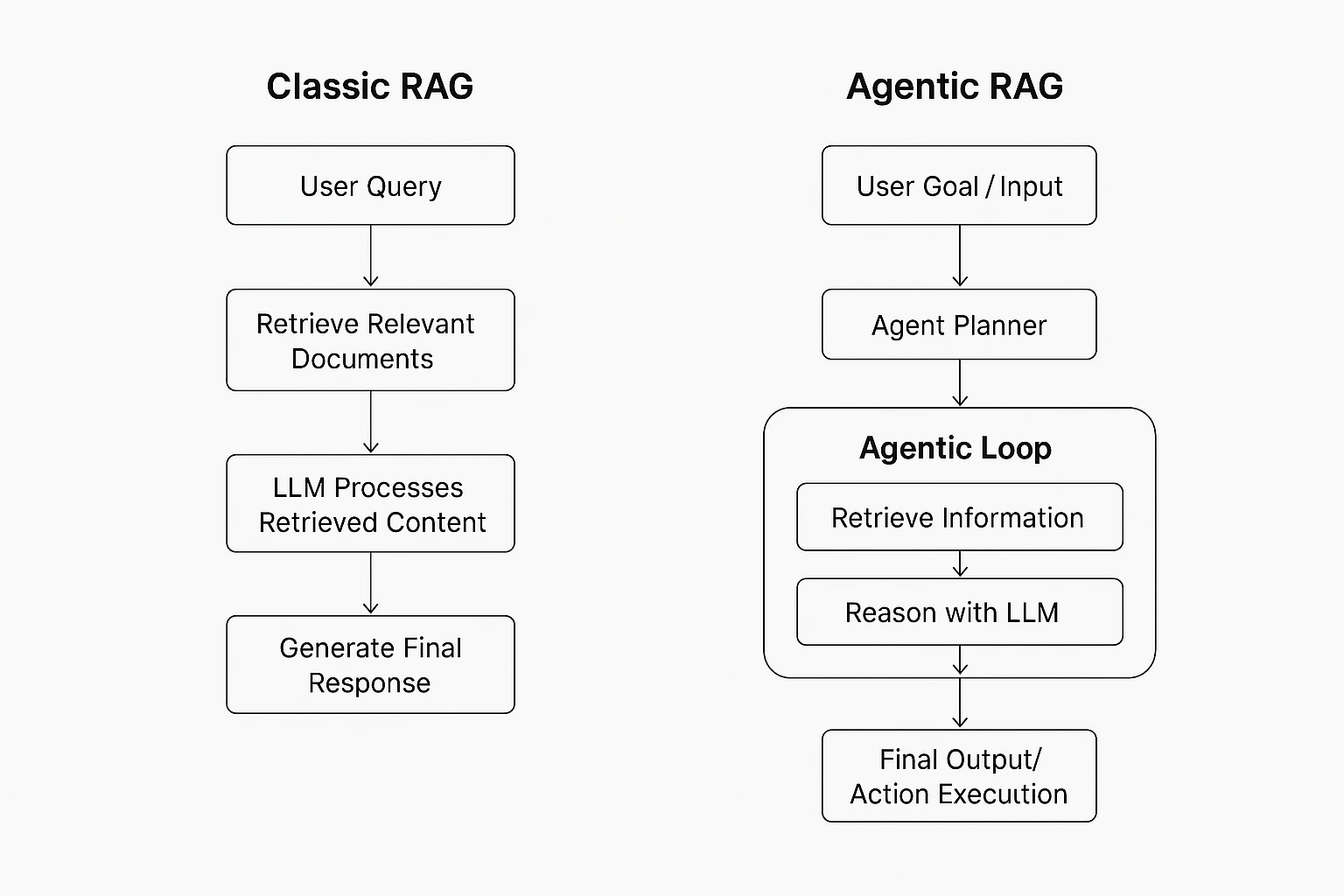
To make that shift clear, here’s a simple comparison between Classic RAG and Agentic RAG:
 13 mins
13 mins











 Talk to Our
Consultants
Talk to Our
Consultants Chat with
Our Experts
Chat with
Our Experts Write us
an Email
Write us
an Email





