


 13 mins
13 mins
May 01, 2025

Over the past few years, AI-native SaaS platforms have evolved at a remarkable pace. Many teams now release AI-driven features every few weeks – copilots, recommendation layers, conversational analytics, automated insights, and so on.
Yet, behind this velocity lies a quiet struggle most teams eventually face: scaling AI performance without slowing down their release cycles.
At Azilen, we’ve seen this pattern across multiple product ecosystems. Even well-architected AI stacks begin to feel the friction when data volumes grow, inference traffic spikes, or retraining cycles become too frequent.
This is exactly where NVIDIA GPU Cloud integration changes the equation.
From our own experience designing and deploying AI systems, the biggest delays rarely come from the model itself. They surface in how the infrastructure handles it.
Teams typically face a few recurring challenges:
→ Inference lag once real users start hitting AI features at scale.
→ Unstable cost patterns as GPU resources remain underutilized or overprovisioned.
→ Slow retraining cycles that force longer release intervals.
→ Complex environment replication, especially across dev, staging, and production.
Traditional infrastructure wasn’t designed for these dynamic AI pipelines. Every new AI feature increases computational demands, while customer expectations for response time and reliability only rise.
NVIDIA’s GPU Cloud integration directly addresses recurring friction points with an infrastructure that accelerates training, streamlines inference, and keeps costs predictable.
Here’s what we’ve consistently observed after implementing it across different stacks and environments.
Provisioning new environments used to take hours or even days, especially when models needed GPU tuning. With NVIDIA AI Enterprise images, teams can spin up GPU-ready environments almost immediately.

Source: NVIDIA
Using NIM microservices, model versions can be deployed as containerized endpoints, easily orchestrated via Kubernetes. We’ve noticed this drastically shortens deployment cycles and brings more consistency between dev and production environments.
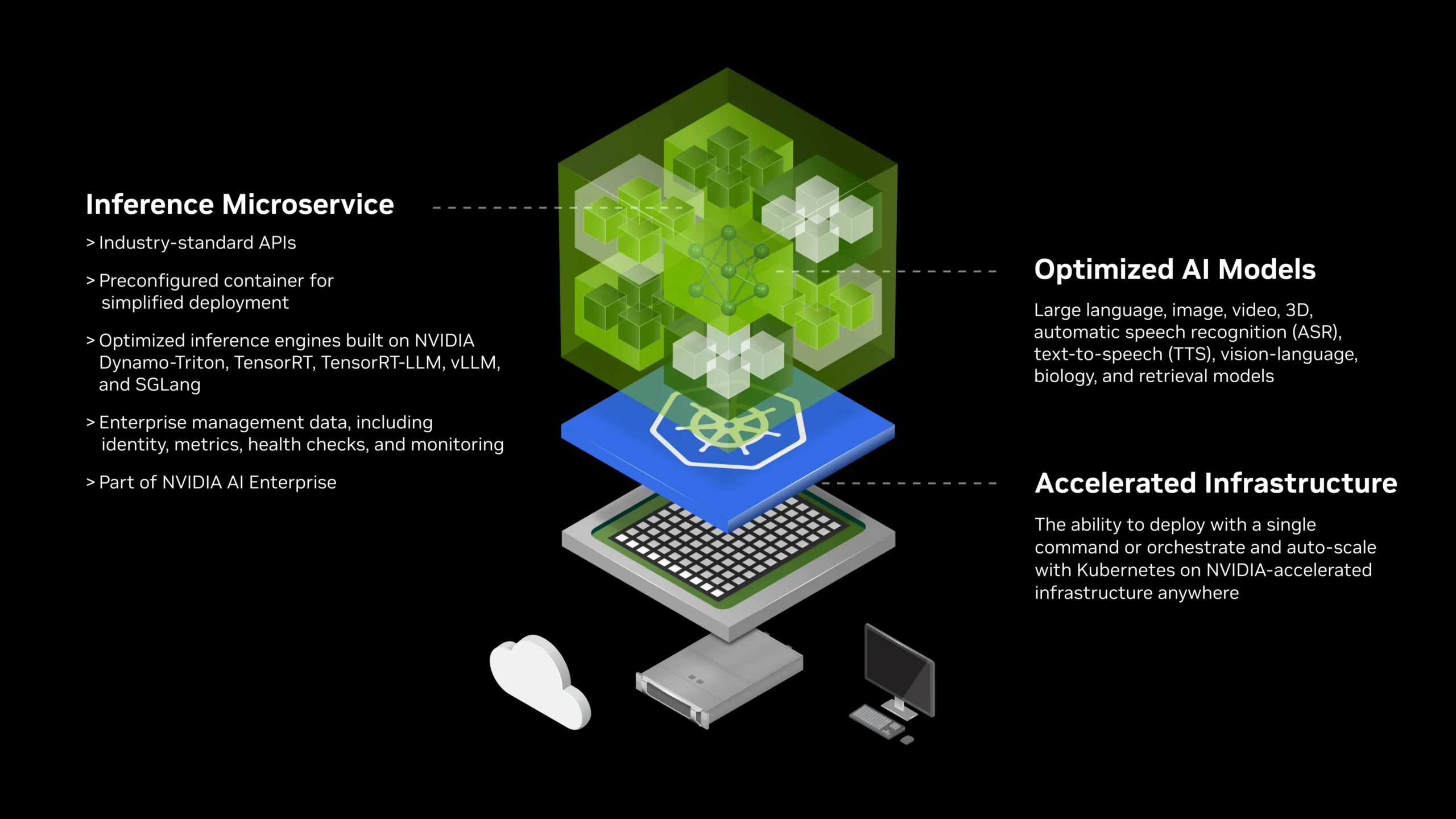
Source: NVIDIA
Low-latency inference has always been a defining factor for product experience. Through TensorRT-LLM and CUDA-X optimizations, NVIDIA’s stack consistently delivers faster throughput without code-level model refactoring.
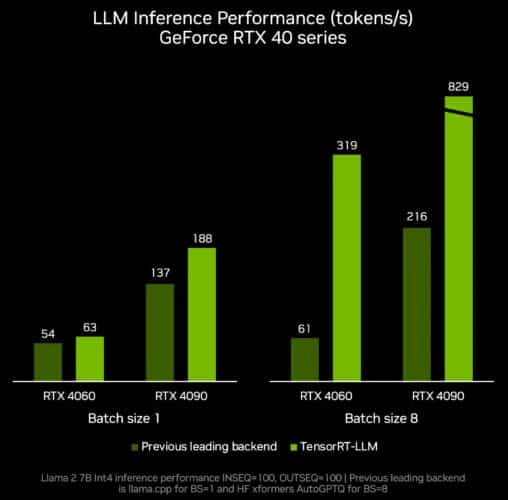
Source: NVIDIA
In one of our internal benchmarks, switching inference pipelines to GPU-optimized serving reduced response time by nearly two-thirds under concurrent load, all with the same model weights.
That’s the kind of improvement that changes the user experience entirely.
Every product team wants to iterate faster, but retraining models often means interrupting live services.
With NVIDIA GPU Cloud integration, we’ve been able to maintain separate GPU pools for training and inference. This setup allows parallel retraining and live serving simultaneously.
Once the new model completes validation, it simply replaces the previous version via the microservice layer. No downtime, no rollback stress. The product team keeps shipping.
GPU resources can be a double-edged sword, powerful yet expensive when idle. We’ve learned that Multi-Instance GPU (MIG) configurations and smart autoscaling policies make all the difference.
By splitting GPUs into smaller compute units and allocating them based on workload intensity, utilization rates rise significantly. Teams get predictable billing and no longer overpay for idle clusters.
This balance between speed and cost-efficiency is one of the most underrated benefits of proper integration.
Over time, most SaaS teams we work with move toward a layered structure that looks like this:
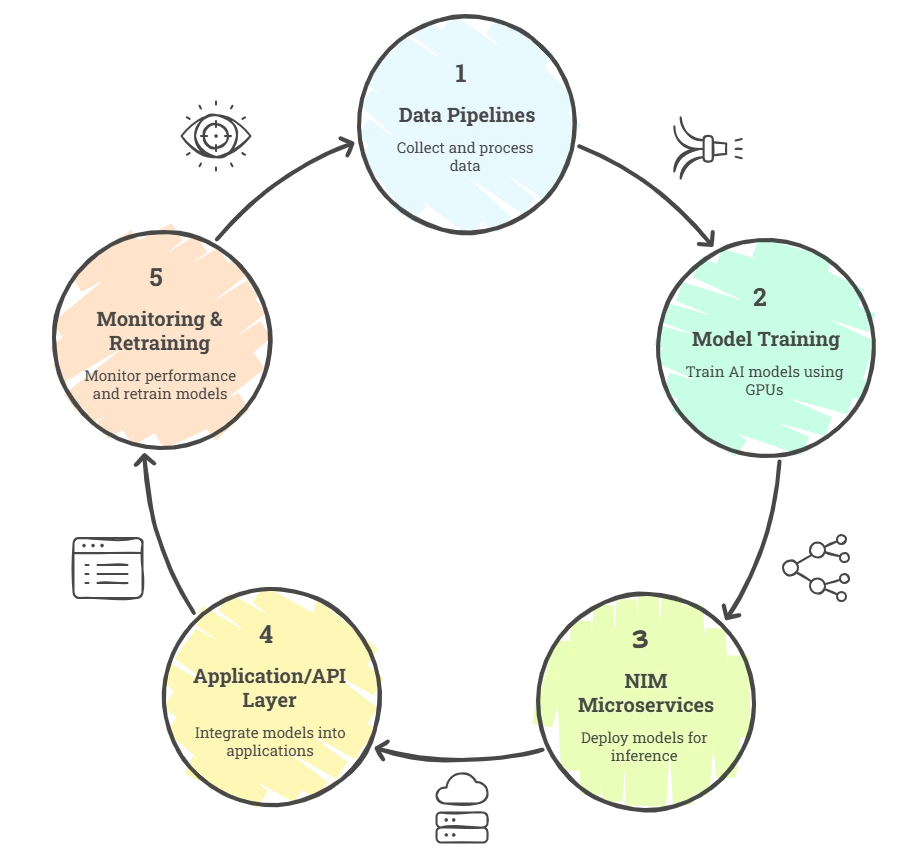
The goal is to keep every layer modular, observable, and GPU-aware.
We’ve seen that once this foundation is in place, scaling from a single AI feature to a full suite of intelligent product capabilities becomes seamless.
From our experience, the success of NVIDIA GPU Cloud integration depends less on tools and more on how the journey is structured.
Here’s how you can move step-by-step to reach stability faster and scale cleaner.
We start by profiling latency, throughput, and concurrency patterns across models.
This analysis helps decide whether to use A100s, L40s, or H100s, and whether workloads belong on shared GPU nodes or dedicated clusters.
The goal here is to find the right fit between workload type and GPU configuration before touching deployment.
Once the performance profile is clear, we rearchitect the stack around GPU-native design.
This involves introducing NVIDIA AI Enterprise, CUDA-X, and NIM microservices as modular layers.
Kubernetes clusters are tuned for GPU scheduling using device plugins and optimized container runtimes.
Data pipelines feeding these models are restructured to ensure GPUs never sit idle waiting for I/O.
We’ve seen that designing this stage well creates the foundation for consistent model performance, no matter how many new features come in later.
After initial integration, we benchmark every major component – model loading, inference latency, memory usage, and GPU occupancy.
Our engineering teams typically use Nsight Systems and NVIDIA Triton Inference Server metrics to identify optimization opportunities.
This early tuning often uncovers bottlenecks that aren’t visible in CPU-based simulations, such as suboptimal batch sizes or data transfer delays. Fixing them up front means fewer surprises once user traffic hits.
The final stage turns the setup into a living, self-adjusting system.
Autoscaling rules are configured through Kubernetes Horizontal Pod Autoscaler (HPA) and NVIDIA GPU metrics, so clusters scale dynamically with traffic.
Separate GPU pools handle training and inference to prevent resource contention.
Retraining pipelines are automated using CI/CD triggers and MLOps workflows – every model update flows through versioning, validation, and GPU deployment automatically.

Usually within the first few sprints. Once your workloads start running on GPU-optimized containers, you’ll notice immediate drops in inference latency. We’ve seen teams experience 2–3x faster inference within days after integration, even before full-scale optimization.
Not necessarily. Most modern AI stacks, especially those using frameworks like PyTorch or TensorFlow, can directly leverage GPU instances. The key work usually lies in optimizing serving layers and automating scaling. A well-structured integration can happen without disrupting your existing model logic.
Speed and stability. Features roll out faster because deployment and retraining cycles run smoothly. Engineers spend less time managing infrastructure and more time improving product intelligence. It’s a visible productivity boost across the release pipeline.
These workloads demand consistent low-latency inference. GPU acceleration paired with TensorRT and CUDA optimizations keeps responses quick, even under concurrent user load. It makes AI-driven interactions feel seamless, which directly impacts user satisfaction.
Yes. With Multi-Instance GPU (MIG) and dynamic autoscaling, you can slice GPU resources based on live workload intensity. That means no idle burn and no sudden cost jumps. Once tuned, it gives predictable monthly billing with optimal utilization.
NVIDIA GPU Cloud (NGC): A cloud-based platform by NVIDIA that provides GPU-optimized software, containers, and pre-trained models to accelerate AI development and deployment. It helps teams run AI workloads faster and more efficiently.
NVIDIA AI Enterprise: A suite of enterprise-grade AI tools, drivers, and frameworks optimized for GPUs. It ensures reliability, performance, and compatibility when deploying AI models in production environments.
NIM (NVIDIA Inference Microservices): Containerized microservices built by NVIDIA that simplify AI model deployment. They allow teams to serve, scale, and manage models just like regular microservices in Kubernetes.
TensorRT: A high-performance deep learning inference library from NVIDIA. It optimizes trained models to deliver faster predictions on GPU hardware without reducing accuracy.
CUDA: NVIDIA’s parallel computing platform and API that lets developers run computations on GPUs. It powers most of the speedups achieved through NVIDIA’s ecosystem.
13 mins 
 15 mins
15 mins 
"*" indicates required fields

5432 Geary Blvd, Unit #527 San Francisco, CA 94121 United States
320 Decker Drive Irving, TX 75062 United States

6d-7398 Yonge St,1318 Thornhill, Ontario, Canada, L4J8J2

71-75 Shelton Street, Covent Garden, London, United Kingdom, WC2H 9JQ

Hohrainstrasse 16, 79787 Lauchringen, Germany

12, Zugerstrasse 32, 6341 Baar, Switzerland

5th floor, Bloukrans Building, Lynnwood Road, Pretoria, Gauteng, 0081, South Africa

12th & 13th Floor, B Square-1, Bopal – Ambli Road, Ahmedabad – 380054
B/305A, 3rd Floor, Kanakia Wallstreet, Andheri (East), Mumbai, India









 Talk to Our
Consultants
Talk to Our
Consultants Chat with
Our Experts
Chat with
Our Experts Write us
an Email
Write us
an Email